AI 白話文之名詞解釋
「只要你懂 AI,AI 就會幫你」
機器學習(Machine Learning)
機器學習(Machine Learning, ML)是一種讓電腦「學習」的技術,讓電腦從中訓練的過程中找出規律。
像訓練一隻貓學會分辨「桌子上的哪些東西可以推下去,哪些不可以」。假設你家的貓很喜歡把桌上的東西推下去,有些東西像是橡皮擦或原子筆,推下去不會造成什麼問題,就算有損失也不大,但如果推下去的是水杯、手機或筆電,這就不是開玩笑的了。
於是你決定要來訓練這隻貓,讓牠學會分辨什麼可以推、什麼不能推。
一開始當貓咪把橡皮擦推下去,你就會摸摸它的頭,給它吃個零食或肉條(我知道不應該這樣鼓勵牠),這樣一來貓咪可能會覺得「推橡皮擦下去是好事」。但如果牠推你的水杯或手機,你會大聲制止它,甚至把牠抱離桌子,讓牠明白「嘿,這東西不能碰」。
慢慢地,牠可能會從中開始學到規律,某些東西推了不會怎麼樣,甚至會有獎勵;而某些大小或形狀的東西推下去會讓鏟屎官生氣,就不要推。即使後來你在桌上放了一個新的、沒看過的玩具,貓咪可能還是從過去學會的規則來判斷出這種東西能不能推。
在機器學習中,這隻貓的行為就像模型的學習過程,桌上的這些東西就是訓練用的資料。你給貓咪的正面和負面回饋,就像訓練模型時的「標籤」。每次貓推倒某個物品並得到反應,牠都在學習不同特徵,比如物品的大小、重量、材質,甚至鏟屎官的表情,來建立「推或不推」的規則。
機器學習的本質,就像訓練這隻貓,提供足夠多的物品和反饋,讓牠自己摸索出規律。貓可能一開始亂推,但經過多次嘗試,最終會知道哪些東西可以推下去,哪些不行。這個過程,就像機器學習模型從數據中學到規律,最後應用到新情況一樣。
講是這樣講,但現實生活中的貓才不會管你這麼多,至少我們家的貓是不受教的。
深度學習(Deep Learning)
機器學習的方式有很多種,「深度學習」也是其中一種,這是讓電腦模仿人腦的運作方式,用一層一層的「神經網路」來學習大量的資料。這有點像教小孩認識新事物,只是這次教的對象是電腦。
假設你是一位耐心的老師(嗯,我不是),小朋友剛開始對動物一無所知。你先給這位小朋友看一張貓的照片,告訴他「這是貓」。小朋友可能會注意到「貓有四隻腳,身體毛茸茸,還有尾巴」。於是小朋友的腦袋裡先記住了這些「特徵」。
接著,你再給他看一張狗的圖片,跟小朋友說「這是狗」。小朋友會開始比較這些動物,發現狗跟貓一樣也有四隻腳和毛茸茸的身體,但耳朵跟尾巴的形狀不太一樣。於是他又記住了這些「特徵」。隨著給他看更多不同的動物圖片,小朋友逐漸能夠學會辨別貓、狗,以及更多的動物,例如兔子、青蛙、小鳥。
在學習過程中,每看一張圖片都是在學習「特徵」,特徵從簡單的顏色、形狀到更複雜的動物的行為模式都有。這些學到的特徵經過一層層分析和篩選,最後形成一套完整的「規則」,即使看到一張完全沒看過的動物照片,過去學會的特徵也能幫助小朋友判斷圖片中的動物是什麼。
特徵→規則
深度學習的「層」其實就像小朋友思考的步驟,從基礎特徵逐漸進入更複雜的判斷邏輯。而這位「老師」的角色就是提供訓練資料,讓機器逐漸變得聰明。總結來說,深度學習就是模仿人類學習事物的過程,但它的「學習速度」和「處理能力」遠超我們!
深度學習是機器學習的一個子集合,專注於使用多層神經網路來模擬人腦的處理方式。
應用場景:影像識別(如人臉辨識)、語音助手(如 Siri)等。
AI 人工智慧(Artificial Intelligence, AI)
AI 像一個超級助手,雖然看起來很聰明(也真的比現在大部份的人類聰明),實際上是靠大量資料和程式設計邏輯讓它「看起來」聰明。
AI 能幫我們完成一堆以前自以為只有人類才能做的事情,像是下棋、分析醫療影像、開車這種需要具備智慧或思考能力的行為,甚至像個音樂家一樣幫你創作一首歌,現在不只是照片,連 3D 動畫做的非常逼真。不過,千萬別被它的「聰明」的樣子給騙了,AI 其實並沒有真正懂你,它只是靠一堆資料和邏輯規則在模仿或猜測人類行為。
如果要用廚房來比喻,AI 就是廚師,而資料就是食材。想要廚師做出一桌美味的菜肴,前提是你得給他足夠新鮮的食材。如果你只給他過期的牛奶或爛掉的青菜,最後端上桌的可能就是一碗奇怪的「創意暗黑料理」。同理,AI 的表現如何,全看你給它的數據是否新鮮、完整,還有設計的規則是否合乎邏輯。
所以說,AI 再厲害,它就是根據規則和資料在模仿而已,並不是真的懂什麼是「智慧」。給它好的食材與指導,它確實能端出讓人眼前一亮的佳餚,只是它不會突然放下鍋鏟跑來跟你討論人生哲學。
AI 並不是真正「懂」我們(至少目前還是這樣),而是靠大量的資料訓練和程式去模仿人類的行為。
應用場景:聊天機器人(如 ChatGPT)、推薦系統、自動駕駛等。
生成式人工智慧(Generative AI)
生成式人工智慧(Generative AI, GenAI)是一種能「創造」內容的人工智慧技術。它不只是回答問題或分析數據,而是可以主動生成文字、圖片、音樂、程式碼,甚至影片。簡單來說,Generative AI 就像一個會創作的「虛擬藝術家」或「數位作家」。
生成式 AI 是靠著學習大量資料來模仿它看到的東西。例如,文字生成模型(像 ChatGPT)會從大量的書籍、文章和對話,學習句子該怎麼組成;圖片生成模型(像 DALL·E)會看過許多圖片,知道色彩和形狀是如何組合的。
它的核心技術是深度學習,訓練過的模型可以根據給定的提示,推測並生成內容。例如:
- 輸入一段文字描述「一隻在月球上的貓」,它就能生成一張相應的圖片。
- 請 AI「幫我寫一封離職信」,它可生成一段自然流暢而且讓老闆無法拒絕的文字。
Generative AI 就像一位很厲害的模仿者,它學會了如何「像專家一樣」寫作、畫畫或作曲。當我們對它說「畫一幅梵谷風格的星空圖」,它不是真的「懂」梵谷的藝術(其實人類都不一定懂),而是基於它學過的資料,生成一幅「看起來」像梵谷畫的作品。
大型語言模型(LLM)
大語言模型(Large Language Model, LLM)是基於 AI 與深度學習的大規模自然語言處理模型,專門用於理解、生成及操作人類語言。LLM 的設計目標是透過龐大的語言數據學習語言結構、語法及上下文關係,從而模擬人類的語言能力。
特性:
- 很多的「參數」:LLM 通常包含數十億到數萬億個參數,這些參數是模型在訓練過程中從數據中學習到的權重,用來捕捉語言特性與模式。
- 海量的訓練:模型的訓練依賴於龐大的資料,例如書籍、文章、網頁等,涵蓋多種語言和主題。
- 通用性:LLM 不僅適用於單一任務,還能應用於多種語言任務,如翻譯、摘要生成、問題回答、內容創作等。
「參數」是什麼意思?
我們小時候在學習語言(中文、英文)的時候,我們要學習很多的語法規則,比如動詞要搭配主詞、句子的語序不能亂等等。對 LLM 而言,這些規則就是「參數」。它們用來告訴模型應該如何看待文字之間的關係。例如:
- 「貓追老鼠」和「老鼠追貓」的是不一樣的意思,模型要學會通過語序來區分差異。
- 當在句子裡遇到沒學過新單字時,它可以用學過的規則搭配上下文,判斷這個字可能的意思。
參數 = 規則
參數的數量通常決定了模型的能力。越多的參數,模型就能知道越多規則,理解越多細微的語言特性,參數比較少的模型可能只能處理像是「天氣很好」之類的簡單句子;隨著參數越多,就能理解更複雜的句子,甚至可以根據上下文生成長篇文章。
不過參數越多,表示需要更強的電腦算力來處理,訓練以及使用的成本都很高。那些 3B、7B 之類的數字,指的是模型參數的數量,通常以英文字母 B(billion)表示「十億」。這些數字代表了模型的規模大小,也可以看作是衡量模型「聰明程度」的一種指標。參數越多,模型越複雜,也越有能力處理更細膩的語言任務。
PS: 為了讓大家更容易理解,這裡用「規則」來做比喻;實際上,參數是模型在訓練過程中自動學習到的「權重(weights)」,它們會反映語言結構與特徵之間的關係,並非單純的人為語法規則而已。
GPT
GPT 的全名是 Generative Pre-trained Transformer,由 OpenAI 開發,它的核心是一種基於深度學習的模型,使用了一種稱為「Transformer」的神經網路架構,這個架構特別擅長處理自然語言相關的任務,例如文字生成、翻譯、摘要等。
- 生成式 (Generative):這表示 GPT 的主要功能是「生成」語言內容。它可以基於輸入的文字提示,生成與上下文相關的連續文字。舉例來說,如果你輸入一個問題,它可以根據已學習的知識提供回答。
- 預訓練 (Pre-trained):模型在使用前已經接受了大規模的資料訓練,例如書籍、文章、網站內容等。這些訓練讓模型學會了語言的基本結構、語法及常見的知識背景。
- 變換器(Transformer):這是一種用於語言處理的神經網路架構,它的優勢在於能夠同時分析句子中的所有詞語,從而理解上下文。Transformer 有點像是一個電影劇本編輯,當你說「英雄最後打敗了壞人」,它能分析劇情中的關鍵角色、動作和情節,甚至還能補充出「英雄最後打敗壞人,拯救了世界,順便贏得了女主角的尊敬,最後還在一起」。這就是為什麼大語言模型擅長生成文章、對話或故事的原因。
工作原理:
- 輸入處理:將輸入的文字轉換為數字表示(向量),以便模型理解。
- 上下文預測:模型利用「注意力機制」分析輸入內容,預測下一個最可能出現的文字。
- 生成輸出:根據預測結果產生文字,並不斷循環,直到完成輸出的內容。
限制:
- 資料偏見:模型訓練於人類撰寫的文字,因此可能繼承人類的偏見。
- 短視近利:在處理特別長的文字時,可能無法完全記住所有細節。
- 沒有真正理解:GPT 並不具備人類的理解能力,它只是在模仿語言模式。
ChatGPT
ChatGPT 是基於 GPT(Generative Pre-trained Transformer)技術的人工智慧聊天程式,由 OpenAI 開發,專門用於進行自然語言互動,就是因為可以聊天,所以才加上 Chat 這個名字。它是一種強大的語言模型,可以模仿人類的語言模式,提供有條理且上下文相關的回應
限制:
- 上下文記憶有限:在比較長的對話中可能無法記住所有細節。
- 資料不一定是最新的:模型僅基於訓練時的資料,無法即時獲取最新資訊。後來 ChatGPT 加入網路查詢功能之後已改善,但目前仍無法得到最新即時資訊。
上下文(Context)
想像一下,你跟朋友在咖啡廳聊天,聊著聊著,突然朋友冒出一句:「對啊,真的很不錯!」。你可能完全不會覺得奇怪,因為你正在跟對方聊天,知道現在正在聊什麼,例如新買的 3D 印表機很好用。但如果你才剛進到咖啡廳,一坐下來朋友直接丟出這句話,你可能會想:「什麼很不錯?是在說什麼?」
這就是「上下文(context)」的重要性。上下文是對話的連結,可以讓一切有邏輯、有條理。如果少了上下文,這些對話或交流就會像是一堆不相關的碎片資料。
上下文在 AI 中的角色
當你在跟 AI 對話時,AI 必須依靠上下文來理解你的需求。如果少了上下文,對話可能變成這樣:
你:「明天會下雨嗎?」
AI:「不會」
你:「那我要帶傘嗎?」
AI:「請問您指的是什麼?」因為 AI 沒有「記住」你上一句講什麼,沒辦法理解你正在問的是「下雨」這件事。所以 AI 雖然好像很厲害,如果沒有特別設定的話,它就只是個金魚腦,不會記得剛剛上一句話講了什麼。
但大家在用 ChatGPT 的時候,應該不會覺得 AI 像失智老人一樣吧,這又是怎麼做到的?簡單來說,ChatGPT 並不像人類一樣有「真正的記憶」,它每次回應時靠的是「帶著所有對話歷史重新思考」。有點像是寫便條紙的時候,第一張記錄「台北的天氣」,第二張寫「下雨」,第三張寫「明天的天氣怎樣?」它每次回答時,會先翻一下前面所有便條紙,然後組合出一個完整的答案。
向量(Vector)
以前在數學或物理課曾經學過,向量有「大小和方向」:
- 大小:向量的「大小」可以理解成整體有多強或多大。例如向量是
[3, 4],這兩個數字可以組成一條線,這條線的長度就是這個向量的「大小」。 - 方向:向量的「方向」就是它指向哪裡。例如
[3, 4]是平面上的一個向量,那它會從原點出發,朝著右上角的方向。
用途:
- 描述事物的特性:像介紹一個人的時候可以用一個向量
[身高, 體重, 年齡]來表示。 - 比較事物的相似性:如果有兩個向量很相似,比如
[175, 70, 25]和[180, 72, 26],我們可以推測這兩個人在身材方面的特徵有點像。 - 計算東西的變化:在物理裡,向量常用來描述力、速度等有方向性的東西,比如「車往北開 60 公里/小時」。
向量就是一組數字,幫我們用簡單的方式描述大小和方向。它可以用來表示特徵、比較相似性,或者計算方向和變化。
嵌入(Embeddings)
是一種將文字、圖片或其他資料轉換為數字向量(vector)的方式。簡單來說,這是一種壓縮且有意義的資料表達形式,讓電腦可以更高效地理解和處理這些資料。用白話來解釋,可以想像 Embeddings 是把複雜的概念轉化成電腦能理解的「座標」,類似的東西會靠的近,不相似的東西則會遠離。
為什麼需要 Embeddings?
讓模型「理解」語意,比如,模型可以知道「貓」和「狗」比較接近,但「貓」和「汽車」就離比較遠。它們的 Embeddings 可能是這樣:
- 貓:
[0.9, 0.8, 0.1] - 狗:
[0.8, 0.9, 0.2] - 汽車:
[0.1, 0.1, 0.9]
類似的應用還有,當我們在搜尋引擎中輸入一個問題,系統可以透過 Embeddings 來找到那些與你的問題語意相似的內容。Embeddings 就像是給每個東西一個「座標」,方便我們知道它跟其他東西的關係。
微調(Fine-Tuning)
想像 LLM 是一個已經讀過世界上所有書的大師,他什麼都懂,但可能不夠專精於你想要的內容。微調的角色就像是一對一的補習班老師,拿一些特定的教材或題目來教這位大師,讓大師在特定領域或任務上表現得更好。例如,你可能希望 LLM 可以幫你生成法律合約、寫醫學相關文章,或是回答技術問題
所以,微調是在調什麼?
挑選資料:
首先,要先準備好專門的資料,這些資料應該和你想要模型處理的任務有關。例如,如果你要讓模型生成電影劇本,你會收集一些高品質的劇本;如果是客服回答,你可能會用大量的對話紀錄作為資料。
更新模型參數:
有了資料後,微調的過程就是讓模型用這些資料來進行再訓練。雖然模型本來就知道很多事情,但透過這個過程,它會特別專注於你提供的資料,調整內部的參數。這就像是告訴模型「這些東西很重要,你要記住!」
避免過度專注:
微調的時候也要小心,如果讓模型只看你提供的資料,可能會出現「過度適應」的情況,有點像在教小孩吃飯,結果你只給他吃一種特定的食物,像是糖果,因為你想讓他特別喜歡這個口味。最後小孩就只想吃糖果,其他什麼菜都不碰了。對模型來說,就是在微調時加入一些多元的資料,或者保留原本模型的一部分知識,讓它能保持更全面的能力,而不會變成只會回答「糖果問題」的專家。
測試與調整:
微調完成後,你需要測試模型,看它在新任務上的表現如何。如果效果不夠理想,就要回去再調整資料或訓練方式,直到達到你的期望。
應用場景:
- 線上客服:調整模型,讓它回答企業常見問題。
- 專業內容生成:生成法律文件、醫學報告等。
- 特定語言或風格:比如生成古文或幽默風格的文章。
檢索增強生成(RAG)
檢索增強生成(Retrieval-Augmented Generation, RAG)是一種讓 AI 模型更聰明回答問題的技術。
它的核心理念是把大型語言模型和外部知識庫結合起來,讓模型不只是靠自己原本記住的東西來回答,而且還能主動查資料,再根據查到的內容生成答案。你可以把 LLM 想像成一個很會寫文章的大學生,但他腦袋裡的知識只有上次考試前讀的課本。RAG 就像給他一個「即時搜尋工具」,讓他先去查最新的資料,再用這些資料來寫答案。這樣生成的回應既有創意又可靠,不會亂講一通。
所以,RAG 在做什麼?
檢索(Retrieval)
想像你問 AI 一個很專業的問題,比如:「這家公司去年第四季的財報怎麼樣?」如果單靠 LLM,它可能會胡亂猜,因為這類最新資訊並不在模型的訓練資料裡。這時,RAG 系統會先去查外部資料庫(比如企業的財報數據、網站或其他文件)。它就像是模型的「小助手」,幫忙先找一些和問題相關的內容。
生成(Generation)
拿到相關資料後,模型就會根據這些資料來生成答案,而不是憑空腦補或瞎掰。
為什麼用 RAG?
- 即時性資訊:因為 LLM 的知識只到訓練時的資料為止(可能是一兩年前的東西),而 RAG 可以查最新資料,像是新聞或公司報告,確保回答不過時。
- 更準確:RAG 用檢索來補充 LLM 的知識盲點,讓回答不只是「聽起來很合理」,而是真的根據實際的資料或文件來生成。
- 客製化:如果你有一個專門的知識庫,比如內部技術文件,RAG 可以幫你把這些資料整理成知識庫,讓模型使用這些資料或文件來生成答案。
應用場景:
- 線上客服:讓 AI 能快速查詢公司的服務項目或 FAQ,回答更精準。
- 專業問答:醫學、法律等領域,AI 能從專業文獻中檢索到正確的答案。
- 內容生成:幫助生成內容時參考相關資料,確保內容有憑有據。
實作參考:https://pythonbook.cc/articles/2024/9/11/rag-workshop
RAG 跟微調(Fine-tuning)的差別:
微調就像請家教,如果你希望你的小朋友變成數學高手,你可以請專業的數學家教來幫他補習,而且是特別針對數學這一科進行密集訓練。經過一段時間的補習後,他就能把數學學得非常專精,甚至還可以去參加數學競賽。微調通常能更快回答和相關領域相關的問題,因為是把相關的知識刻在腦袋裡了。
而 RAG 比較像是給學生一台隨身查資料的手機或平板電腦,裡面連接了最新的資料庫,有需要的話隨時可以查資料。當遇到問題時,不一定需要完全依靠自己的記憶,而是先用平板查到相關的資訊,然後再根據這些資料回答問題。比如有人問:「最近的氣候變化報告說了什麼?」他可以馬上從平板裡找出最新的研究,然後給出一個有條理的回答。
如果你需要的是「專精型學生」,像是要寫小說或專門回答特定領域問題,請找家教幫他補習(用微調)。如果你需要的是「靈活型學生」,隨時能應對各種問題,還要有最新的資訊,就給他一台平板(用 RAG)。
別誤會,這兩種做法並沒有衝突,如果想要,可以兩者併行,送去補習又給他一個厲害的平板查資料。
新聞
台北捷運 AI 客服機器人 https://www.ithome.com.tw/news/166191
AI Agent
AI Agent(人工智慧代理人)是一種可以「自主執行任務」的電腦程式,就像一個聰明的數位助理,根據我們設定的目標,自己決定要做什麼、怎麼做。它不需要你事事指揮,而是會根據環境和任務的需要,自行採取行動,幫你解決問題。
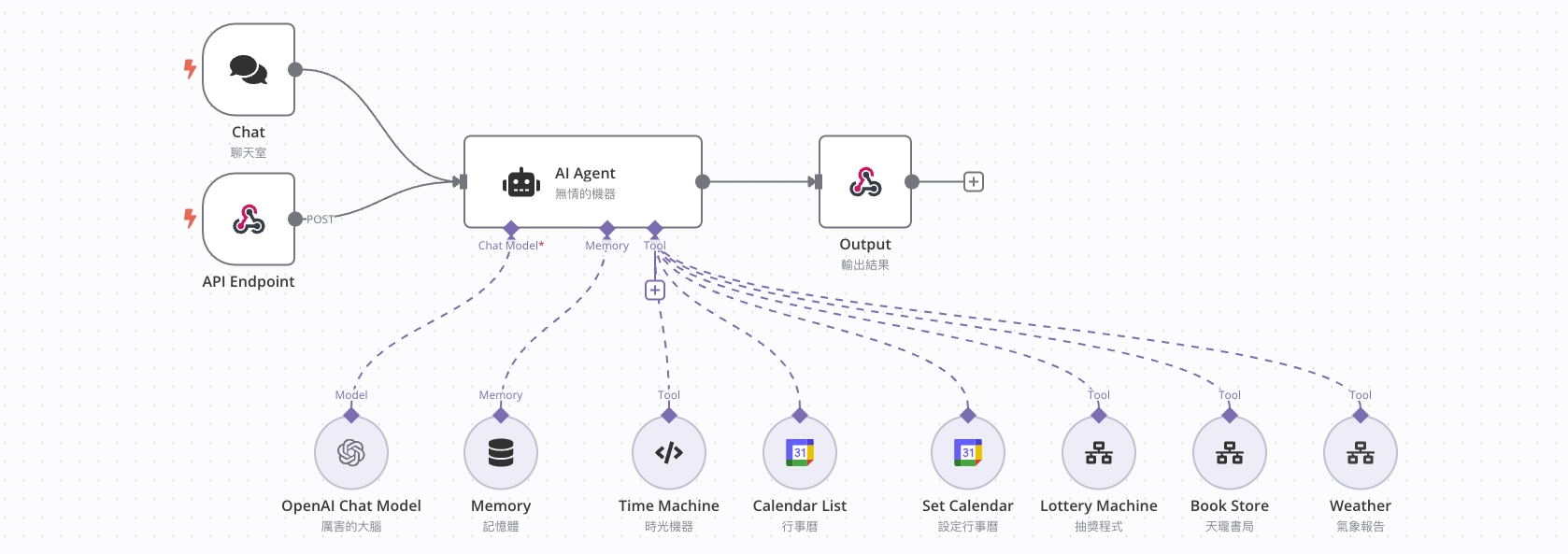
運作原理:
感知環境(Perception):
它會「觀察」周圍的資訊,可能來自數據、使用者指令,或者外部系統的回饋。比如,AI Agent 可以感知天氣預報資料,知道今天會下雨。
思考和決策(Decision Making):
感知完後,它會分析手上的資訊,根據目標來「決定下一步」該做什麼。例如,知道下雨後,AI Agent 可能決定提醒你帶雨傘。
執行行動(Action):
最後,它根據決策去執行任務,比如發送通知、完成一筆交易,甚至幫你控制一個機器人去完成某項工作。
AI Agent 的關鍵特點是「自主性」,不需要你一步步下指令。你可以跟這位助理說:「幫我安排今天的行程」,它不只是記錄你的要求,而是會主動去查你的日曆、交通狀況,甚至天氣,然後給出一個完整的行程計畫。如果有突發狀況,比如會議延誤,這位助理還會幫你重新調整時間,確保行程順利。
Agentic AI
代理人工智慧指的是自主的 AI 系統,能夠以最少的人類干預做出決策。這些系統可以從新數據中學習,並透過動態適應新情況來解決複雜問題。例如,零售商可以使用代理人工智慧來個人化購物體驗,醫療保健提供者則可利用該技術來分析患者數據。然而,隨著先進的人工智慧模型變得越來越容易獲得,網路犯罪也可能利用該技術來欺騙受害者,使用此類技術時需保持謹慎,確保有適當的監督和測試。
| 特性 | AI Agent | Agentic AI |
|---|---|---|
| 自主性 | 低到中等,需要人類干預 | 高度自主,幾乎不需干預 |
| 應用範圍 | 專注於特定任務 | 多任務、多領域 |
| 決策能力 | 依賴預設規則與範圍 | 可動態推理,適應新情況 |
| 學習能力 | 有限,透過預訓練或微調獲得能力 | 可進行自我學習 |
| 範例 | ChatGPT、Tesla 自動駕駛 | Skynet |
Automation 自動化
自動化(Automation)就是讓機器或系統自動完成重複性、機械性的工作,而不需要人類一步步指揮或操作。簡單來說,自動化就像是請了一個「不累、不抱怨、效率高」的幫手,幫你把枯燥的事情做好。例如:
咖啡機的自動沖泡:
想像一下,你早上剛睡醒,按下咖啡機的按鈕,咖啡豆被磨碎、熱水流過,最後一杯熱騰騰的咖啡出現在你面前。這就是自動化的好處:不需要你每次都自己磨豆、燒水、調配,只要設定好流程,機器就幫你完成。
洗衣機的全自動洗衣:
以前洗衣服需要手洗、搓揉、漂洗,現在只要把衣服丟進洗衣機,按下按鈕,從洗到脫水,全都幫你搞定。這樣,你就能省下時間去做其他更重要的事情。
現成工具:Zapier、Make、n8n